Linda: Less is More
This chapter discusses one of the most well known of Kahneman and Tversky's experiments. This is the so-called "Linda" case, and it's intended to illustrate a particular fallacy of probabilistic reasoning that came to be called the "conjunction fallacy". Like last chapter, it involves the representativeness heuristic (judging the probability of an something in terms of how similar that something is to a stereotype), and our tendency to ignore base rates when making these judgments.
1. Here's a description of a hypothetical woman named Linda:
Linda is thirty-one years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in antinuclear demonstrations.
Subjects are given a list of eight possible scenarios for Linda and asked to rank them in terms of which scenarios are more or less likely to be true for Linda. Here they are:
People tend to agree that Linda is a very good fit for an active feminist, a good fit for someone who works in a bookstore and takes yoga classes, and a poor fit for a bank teller or an insurance salesperson.
2. Question:
Does Linda look more like a bank teller, or more like a bank teller who is active in the feminist movement?
3. Subjects tend to judge the latter more likely than the former. That is, they judge
P(Linda is bank teller) < P(Linda is a bank teller AND Linda is active in the feminist movement)
Given the description of Linda, THIS scenario seems "more like" the person we imagine in that description.
4. This judgement violates a basic rule of probability theory:
Given two events A and B, and the probabilities of these events P(A) and P(B), it is always true that the probability of the CONJUNCTION of both events, P(A and B), is SMALLER than the probability of each of the events individually. That is,
P(A) > P(A and B)
and
P(B) > P(A and B)
always, as a matter of sheer logic.
1. Here's a description of a hypothetical woman named Linda:
Linda is thirty-one years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in antinuclear demonstrations.
Subjects are given a list of eight possible scenarios for Linda and asked to rank them in terms of which scenarios are more or less likely to be true for Linda. Here they are:
- Linda is a teacher in an elementary school.
- Linda works in a bookstore and takes yoga classes.
- Linda is active in the feminist movement.
- Linda is a psychiatric social worker.
- Linda is a member of the League of Women Voters.
- Linda is a bank teller.
- Linda is an insurance salesperson.
- Linda is a bank teller and is active in the feminist movement.
People tend to agree that Linda is a very good fit for an active feminist, a good fit for someone who works in a bookstore and takes yoga classes, and a poor fit for a bank teller or an insurance salesperson.
2. Question:
Does Linda look more like a bank teller, or more like a bank teller who is active in the feminist movement?
3. Subjects tend to judge the latter more likely than the former. That is, they judge
P(Linda is bank teller) < P(Linda is a bank teller AND Linda is active in the feminist movement)
Given the description of Linda, THIS scenario seems "more like" the person we imagine in that description.
4. This judgement violates a basic rule of probability theory:
Given two events A and B, and the probabilities of these events P(A) and P(B), it is always true that the probability of the CONJUNCTION of both events, P(A and B), is SMALLER than the probability of each of the events individually. That is,
P(A) > P(A and B)
and
P(B) > P(A and B)
always, as a matter of sheer logic.
|
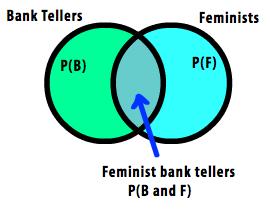
But the judgment about Linda goes like this: Let B = Linda is a bank teller, and F = Linda is active in the feminist movement. Then what people are saying is they believe the CONJUNCTION of two events is more probable than one of the individual events.
P(B) < P(B and F) This is why Kahneman and Tversky called it the "conjunction fallacy", because it violates the rule for how to reason with the probabilities of conjunctions of events . |
Kahneman interprets this as a "failure of System 2". System 1 delivered the judgment based in representativeness (closeness to a stereotype) to System 2. System 2 is responsible for logical "fact-checking", but in this case it fails to do its job.
5. The result shows up in lots of different experimental setups:
Compare the likelihood of these scenarios:
1. There is a massive flood somewhere in North American next year, in which more than 1000 people drown.
2. There is an earthquake in California next year, causing a flood in which more than 1000 people drown.
People tend to judge scenario 2 as more likely than scenario 1, even though 1 is objectively more probable than 2, since it includes 2 as a special case (see the note about the conjunction fallacy above).
6. It's important to see how judgments of coherence and plausibility are playing a role in this error. Consider these two pairs of statements:
1. Mark has hair.
2. Mark has blond hair.
1. Jane is a teacher.
2. Jane is a teacher and walks to work.
People don't tend to make the mistake with examples like these. Why not? Because the additional detail is just more detail.
It doesn't trigger a stereotype in our heads. It doesn't offer a more plausible or coherent narrative to help us make sense of the scenario. So System 2 correctly makes the judgment based on the objective probabilities.
7. There are lots of factors that can influence how likely people are to commit the conjunction fallacy. One of the most well-known is that when people are asked the questions in terms of natural frequencies ("how many?", "what fraction?", etc.) rather than in terms probabilities or percentages ("what is more probable?", "estimate the percentage"), they're less prone to the error. This is probably because this language naturally invokes a spatial representation of the problem, where set and subset relationships are clear. The language of probability and percentages is more abstract, it seems, and fails to evoke a spatial picture of the problem.
This is one of the most frequently discussed "de-biasing" techniques when it comes to reasoning with probabilities. If you give people the information in terms of natural frequencies and proportions rather than in terms of probabilities or percentages, their probability judgments are more reliable (in some cases, significantly so).
Compare the likelihood of these scenarios:
1. There is a massive flood somewhere in North American next year, in which more than 1000 people drown.
2. There is an earthquake in California next year, causing a flood in which more than 1000 people drown.
People tend to judge scenario 2 as more likely than scenario 1, even though 1 is objectively more probable than 2, since it includes 2 as a special case (see the note about the conjunction fallacy above).
6. It's important to see how judgments of coherence and plausibility are playing a role in this error. Consider these two pairs of statements:
1. Mark has hair.
2. Mark has blond hair.
1. Jane is a teacher.
2. Jane is a teacher and walks to work.
People don't tend to make the mistake with examples like these. Why not? Because the additional detail is just more detail.
It doesn't trigger a stereotype in our heads. It doesn't offer a more plausible or coherent narrative to help us make sense of the scenario. So System 2 correctly makes the judgment based on the objective probabilities.
7. There are lots of factors that can influence how likely people are to commit the conjunction fallacy. One of the most well-known is that when people are asked the questions in terms of natural frequencies ("how many?", "what fraction?", etc.) rather than in terms probabilities or percentages ("what is more probable?", "estimate the percentage"), they're less prone to the error. This is probably because this language naturally invokes a spatial representation of the problem, where set and subset relationships are clear. The language of probability and percentages is more abstract, it seems, and fails to evoke a spatial picture of the problem.
This is one of the most frequently discussed "de-biasing" techniques when it comes to reasoning with probabilities. If you give people the information in terms of natural frequencies and proportions rather than in terms of probabilities or percentages, their probability judgments are more reliable (in some cases, significantly so).